Este estudo integra o Projeto Final do Programa Embarcatech, iniciativa do Governo Federal realizada em parceria com o Softex e os Institutos Federais do Nordeste em 2025. O objetivo central é apresentar, de forma didática e tecnicamente fundamentada, os principais métodos, modelos e estratégias usados na análise e previsão de séries históricas — um tema essencial para sistemas embarcados inteligentes, IoT, automação industrial e aplicações que envolvem tomada de decisão baseada em dados. Ao incluir tanto métodos estatísticos tradicionais quanto modelos modernos baseados em Deep Learning e arquiteturas de larga escala como o Granite TTM, este estudo oferece uma visão completa e prática para estudantes, pesquisadores e profissionais que desejam aplicar previsões temporais em ambientes reais.
1. Introdução às Séries Históricas e à Previsão Temporal
A análise de séries históricas corresponde ao estudo de variáveis ao longo do tempo com o objetivo de compreender padrões, detectar tendências e gerar previsões capazes de orientar decisões. Em engenharia, economia, meteorologia, telecomunicações, IAoT e ciência de dados, lidar com esse tipo de dado é essencial para antecipar comportamentos futuros e mitigar incertezas. Ao contrário de outros tipos de análise estatística, séries temporais exigem uma abordagem consciente da dimensão temporal: cada observação está ligada à anterior e influencia diretamente a seguinte.
Uma série histórica pode ser vista como uma sequência ordenada de valores ( x(t) ), onde cada elemento representa o estado de uma variável em um instante específico. Essa sequência carrega padrões estruturais que surgem naturalmente nos fenômenos reais: tendências de crescimento ou queda, ciclos sazonais, oscilações de curto prazo, ruído estocástico e eventos abruptos. Assim, a análise não consiste apenas em observar números, mas em identificar a arquitetura temporal subjacente que governa sua evolução.
A previsão (forecasting) baseia-se em transformar esse conhecimento estrutural em modelos matemáticos capazes de extrapolar o comportamento observado. Tais modelos podem ir desde equações estatísticas simples, como médias móveis, até estruturas sofisticadas baseadas em aprendizado de máquina e modelos de grande escala, como LLMs (Large Language Models) especializados em previsão, por exemplo, o Granite TTM da IBM — um modelo temporal treinado especificamente para identificar padrões complexos, analisar janelas temporais longas e realizar inferência sobre múltiplas variáveis simultaneamente. A diversidade de abordagens reflete a natureza multifacetada das séries: não existe um modelo universal, mas sim uma escolha cuidadosa orientada por propósito, qualidade dos dados e comportamento do fenômeno.
Este artigo explora de forma didática todos esses aspectos. Iniciaremos com a classificação das variáveis envolvidas (endógenas, exógenas, discretas, contínuas, categóricas), essenciais para orientar o tipo de modelagem utilizado. Em seguida, vamos percorrer os principais métodos clássicos — decomposição, suavização exponencial, ARIMA, modelos estruturais — até chegar às técnicas avançadas de Deep Learning, Transformers temporais e modelos de larga escala como o Granite TTM. Por fim, serão apresentadas estratégias de obtenção das previsões e boas práticas para aplicações reais.
2 — Tipos de Variáveis em Séries Temporais
A construção de qualquer modelo de previsão começa pelo entendimento correto das variáveis envolvidas. Em séries históricas, a forma como um fenômeno é mensurado determina diretamente quais ferramentas estatísticas podem ser aplicadas, quais transformações são necessárias e como a modelagem deve interpretar o comportamento dos dados. Assim, antes mesmo de falar em ARIMA, LSTM ou Granite TTM, é fundamental compreender a taxonomia das variáveis.
As variáveis podem ser classificadas inicialmente segundo sua natureza numérica, distinguindo-se entre variáveis contínuas e discretas. Variáveis contínuas representam grandezas capazes de assumir infinitos valores dentro de um intervalo — como temperatura, tensão elétrica, consumo energético ou velocidade do vento. Já as variáveis discretas aparecem em forma de valores inteiros, geralmente representando contagens, eventos ou unidades bem definidas, como quantidade de acessos a um servidor por minuto ou o número de transações financeiras por hora. Na prática, ambos os tipos aparecem em séries temporais, mas a escolha de modelos matemáticos muda conforme o tipo: modelos baseados em distribuições de Poisson, por exemplo, são mais adequados para séries discretas de contagem.
Outra divisão importante considera o papel da variável dentro do sistema observado. As variações de uma série podem depender apenas de si mesma — como é o caso de temperaturas diárias ou cotação cambial — ou podem ser influenciadas por fatores externos mensuráveis. Esse é o ponto em que distinguimos variáveis endógenas e exógenas. Variáveis endógenas são aquelas cuja dinâmica pode ser descrita, em grande parte, por sua própria história; tornam-se a base de modelos autorregressivos que utilizam apenas o próprio passado da série para realizar previsão. Por outro lado, variáveis exógenas introduzem informações externas que afetam o sistema. Isso inclui desde condições climáticas que afetam consumo energético até campanhas de marketing que influenciam vendas. Incorporá-las no modelo cria versões mais completas, como ARIMAX, VARX ou modelos híbridos modernos que integram múltiplas janelas temporais e diferentes fontes de informação.
Há ainda a classificação por tipo de medição, que separa variáveis em nominais, ordinais, intervalares e de razão. Embora séries nominais (como estados “ativo/inativo”) não permitam operações matemáticas tradicionais, elas são extremamente relevantes em cenários como telemetria de equipamentos, logs de sistemas ou classificação de eventos. Em contraste, variáveis intervalares e de razão — como temperatura em Celsius ou consumo de combustível em litros — possibilitam modelagem matemática direta e são as mais utilizadas em previsões quantitativas.
Compreender essas categorias é essencial para definir as transformações necessárias ao pré-processamento, como normalização, diferenciação, padronização e tratamento de outliers. Da mesma forma, certos algoritmos exigem tipos específicos de variáveis: métodos de regressão clássica pressupõem variáveis contínuas ou discretas numéricas, enquanto arquiteturas baseadas em Transformers podem lidar simultaneamente com variáveis heterogêneas, desde que recebam embeddings adequados. A partir dessa base conceitual, cada técnica de previsão será explorada nos capítulos seguintes com maior profundidade.
3 — Variáveis Endógenas e Exógenas em Profundidade
A distinção entre variáveis endógenas e exógenas é um dos pilares da modelagem de séries históricas. Embora o conceito pareça simples à primeira vista, seu impacto na qualidade das previsões é profundo. Determinar corretamente o papel de cada variável evita erros de interpretação, melhora a capacidade preditiva e permite construir modelos mais robustos para fenômenos reais, especialmente aqueles influenciados por múltiplos fatores.
As variáveis endógenas são aquelas cujas oscilações podem ser explicadas principalmente pelo próprio comportamento ao longo do tempo. Em termos matemáticos, isso significa que a série possui autocorrelação significativa; seu passado contém informações suficientes para estimar seu futuro. Modelos autorregressivos são construídos com essa premissa, usando valores defasados — chamados lags — como entrada. Um exemplo clássico é a demanda energética de uma região, que costuma seguir padrões diários e sazonais relativamente previsíveis sem depender exclusivamente de fatores externos. Essa autorreferência faz com que métodos como AR, ARIMA e modelos estruturais como ETS funcionem adequadamente, pois se baseiam na estrutura da própria série.
As variáveis exógenas, por outro lado, introduzem influência externa que modifica ou condiciona o comportamento da variável principal. São elementos que não fazem parte da série que queremos prever, mas exercem impacto direto sobre ela. Um exemplo é o uso de temperatura (exógena) para prever consumo de ar-condicionado (endógena), ou o uso de índice de inflação para estimar variação do câmbio. Em sistemas industriais, fatores como carga mecânica, umidade, pressão atmosférica e até ciclos de produção podem atuar como variáveis exógenas. Incorporá-las nos modelos permite capturar relações de causa e efeito mais amplas, transformando modelos em versões expandidas — ARIMAX, SARIMAX, VARX, redes neurais multivariadas e Transformers temporais multivariados.
A presença de variáveis exógenas amplia não apenas o volume de dados, mas a complexidade analítica. Torna-se necessário avaliar correlações e defasagens cruzadas, verificando se e como uma variável exógena antecede o comportamento da variável prevista. Além disso, o pré-processamento deve ser extremamente cuidadoso: variáveis externas podem vir em escalas diferentes, apresentar ruídos distintos ou mesmo não serem estacionárias. Normalização e padronização tornam-se imprescindíveis, assim como testes de causalidade, como o teste de causalidade de Granger, frequentemente empregado para verificar se uma variável exógena realmente melhora a previsão.
Com o avanço dos modelos de larga escala e das arquiteturas de Deep Learning, tornou-se possível integrar simultaneamente dezenas de variáveis endógenas e exógenas. Modelos especializados como o Granite TTM — projetado para previsão temporal multivariada — conseguem transformar essas variáveis em embeddings e analisar relações não lineares complexas ao longo de diversas janelas temporais. Assim, a distinção entre endógenas e exógenas continua válida, mas o paradigma de modelagem se torna significativamente mais rico. O tratamento adequado dessas variáveis é a base para todas as técnicas que exploraremos nos próximos capítulos.
4 — Métodos Matemáticos Fundamentais para Séries Históricas
Os métodos matemáticos clássicos formam a base sobre a qual toda a modelagem moderna de séries históricas é construída. Mesmo com o avanço de modelos neurais e arquiteturas como Transformers, muitas aplicações industriais, financeiras e científicas ainda dependem de técnicas tradicionais pela sua robustez, interpretabilidade e eficiência computacional. Compreender esses fundamentos não apenas facilita o uso dos modelos avançados, mas também revela limitações e características intrínsecas dos dados que muitas vezes algoritmos complexos não deixam explícitas.
Um ponto central nesses métodos é a decomposição estrutural da série. A maioria dos fenômenos temporais pode ser decomposta em três componentes principais: tendência, sazonalidade e ruído irregular. A tendência captura o movimento de longo prazo; a sazonalidade descreve padrões repetitivos dentro de períodos específicos; e o ruído representa variações não estruturadas. Técnicas como decomposição clássica, STL (Seasonal-Trend Decomposition using Loess) e X-13 ARIMA-SEATS aplicam esse princípio para isolar e analisar cada componente. A partir dessa separação, modelos subsequentes podem focar apenas no comportamento residual ou reconstruir a série com maior precisão.
Entre os métodos preditivos mais utilizados, a Suavização Exponencial ocupa posição central. Ela atribui pesos decrescentes para observações antigas, enfatizando mais fortemente os dados recentes. A versão simples, chamada SES (Simple Exponential Smoothing), é adequada para séries sem tendência ou sazonalidade. Para fenômenos mais complexos, surge a família Holt-Winters, em versões aditivas e multiplicativas, capazes de capturar tanto tendências quanto ciclos sazonais. Esses métodos seguem princípios simples, mas permitem resultados extremamente eficazes em sistemas de produção, controle de estoque, telecomunicações e previsão de curto prazo.
Outro grupo de modelos fundamentais é a família ARIMA (AutoRegressive Integrated Moving Average). O componente autorregressivo (AR) estima valores futuros com base em observações passadas; o componente de média móvel (MA) modela choques aleatórios como combinações lineares de erros passados; e o termo de integração (I) torna a série estacionária, removendo tendências através de diferenciação. Quando a série apresenta sazonalidade, utiliza-se SARIMA, que adiciona termos sazonais autorregressivos e de média móvel. A grande vantagem do ARIMA é sua capacidade de capturar dependências temporais de forma rigorosa, sendo amplamente utilizado em econometria, análise energética e telecomunicações.
Em contextos multivariados, os modelos VAR (Vector AutoRegression) se destacam ao generalizar a ideia autorregressiva para múltiplas variáveis interdependentes. Isso é especialmente útil quando fenômenos apresentam causalidade cruzada, como temperatura, carga elétrica e pressão atmosférica em sistemas energéticos. Os modelos VAR conseguem capturar relações simultâneas e defasadas entre variáveis endógenas e, quando necessário, incorporar variáveis exógenas por meio de versões expandidas como VARX.
A despeito de sua idade, esses métodos continuam essenciais. Eles oferecem interpretabilidade que modelos avançados não possuem e servem como referência para validar resultados obtidos com estruturas modernas, como redes neurais e modelos de larga escala. Nos próximos capítulos, avançaremos para técnicas de Deep Learning, Transformers temporais e modelos especializados como o Granite TTM, mostrando como eles expandem e modernizam essa base matemática clássica.
5 — Modelos Modernos de Previsão: Deep Learning e Large-Scale Time Series Models
A evolução da capacidade computacional e o avanço das arquiteturas neurais transformaram profundamente a análise de séries históricas. Fenômenos antes modelados exclusivamente por métodos lineares passaram a ser tratados por estruturas capazes de capturar relações não lineares, dependências de longo prazo e interações complexas entre múltiplas variáveis. Essa transição abriu espaço para modelos de Deep Learning e, mais recentemente, para modelos de larga escala especializados em séries temporais, capazes de operar em níveis antes inacessíveis.
Entre os primeiros saltos conceituais estão as Redes Recorrentes (RNNs) e suas variantes, como LSTM (Long Short-Term Memory) e GRU (Gated Recurrent Unit). Essas arquiteturas foram concebidas para superar limitações de dependência curta em séries temporais, introduzindo mecanismos de memória que permitem capturar padrões prolongados. Em modelos LSTM, portas de entrada, saída e esquecimento controlam a retenção de informação, tornando-os eficazes em aplicações como previsão de tráfego, consumo energético e séries financeiras. Contudo, mesmo essas redes apresentam dificuldades quando a série contém múltiplas escalas temporais ou grande volume de variáveis exógenas.
Esse cenário impulsionou o desenvolvimento de modelos baseados em convoluções temporais, como TCN (Temporal Convolutional Networks), que utilizam convoluções dilatadas para capturar dependências longas sem recorrer ao mecanismo recorrente. Apesar do bom desempenho, o avanço mais significativo veio com a introdução dos Transformers, originalmente aplicados a processamento de linguagem natural. A chave desses modelos — o mecanismo de atenção (attention mechanism) — permite analisar diferentes partes da série simultaneamente, atribuindo pesos para identificar quais pontos temporais realmente influenciam a previsão. Isso abriu caminho para architectures como Informer, Autoformer, FEDformer e DLinear, todas projetadas especificamente para previsão temporal em larga escala.
A combinação desses desenvolvimentos culminou no surgimento de modelos especializados e treinados em grandes volumes de dados temporais, chamados Time Series Foundation Models. Entre eles, destaca-se o Granite TTM (Time Series Model), parte da família Granite da IBM. Diferentemente dos LLMs generalistas, esse modelo é treinado exclusivamente sobre dados temporais multivariados, aprendendo padrões universais de tendência, sazonalidade, anomalias e relações cruzadas entre variáveis. Seu mecanismo de multi-attention permite correlacionar dezenas ou centenas de variáveis endógenas e exógenas, ao mesmo tempo em que identifica quais janelas temporais mais contribuem para previsões robustas.
Além do Granite TTM, outras arquiteturas semelhantes vêm sendo exploradas por empresas e centros de pesquisa: Chronos, Moirai, TimeGPT, Lag-LLM e modelos baseados em S4 (Structured State Space Models), que reintroduzem conceitos matemáticos clássicos em representações neuronais otimizadas. A principal característica desses modelos de larga escala é a capacidade de generalizar padrões mesmo quando há falta de dados, ruído, desbalanceamento ou ausência de estacionaridade — problemas comuns em contextos industriais, IoT e sistemas de energia.
O avanço desses modelos não substitui completamente os métodos clássicos, mas redefine a estratégia de previsão: o foco desloca-se da construção manual do modelo para a definição correta das variáveis, da janela temporal, do horizonte de previsão e da estratégia de fine-tuning. Essa mudança será discutida com mais detalhes no próximo capítulo, dedicado às estratégias práticas de obtenção de previsões em ambientes reais.
6 — Estratégias Práticas de Obtenção de Previsões
A construção de previsões eficazes não depende apenas da escolha do modelo, mas da estratégia completa que envolve preparação dos dados, definição das janelas temporais, seleção das variáveis, configuração do horizonte de previsão e validação sistemática. Em aplicações reais — como energia, indústria, varejo, IoT, mercado financeiro ou telecomunicações — o maior desafio não está no algoritmo em si, mas na metodologia usada para extrair previsões confiáveis de forma consistente. Este capítulo descreve as principais estratégias empregadas para transformar o modelo escolhido em previsões operacionais.
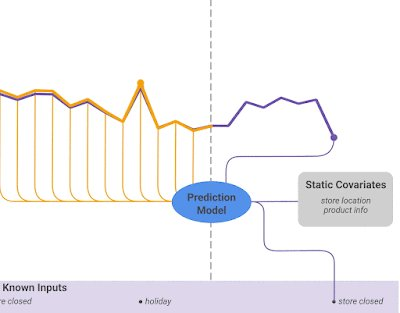
O ponto de partida é a janela de entrada (input window). Modelos baseados em deep learning e Transformers não observam a série infinita; eles analisam blocos temporais. A escolha do tamanho dessa janela determina quanto do passado estará disponível para gerar a previsão. Fenômenos com alta sazonalidade, como demanda de energia, exigem janelas longas que capturem padrões diários, semanais e anuais. Já fenômenos de alto dinamismo, como tráfego de rede ou variações bruscas de sensores industriais, podem se beneficiar de janelas mais curtas, focadas em pequenas variações de curto prazo.
O segundo elemento crucial é o horizonte de previsão (forecast horizon), que define se o modelo fará previsões de curto, médio ou longo prazo. Previsões unipasso (one-step ahead) normalmente são mais precisas, pois utilizam dados muito recentes. Entretanto, quando é necessário prever vários passos à frente, duas abordagens principais podem ser adotadas: a previsão recursiva, em que cada previsão alimenta a entrada do passo seguinte, e a previsão direta, onde o modelo aprende a prever vários horizontes simultaneamente. Modelos modernos, como Granite TTM e variantes de Transformers, são particularmente eficazes em previsões diretas multivariadas, pois analisam simultaneamente todo o contexto temporal.
Outro elemento estratégico fundamental é o tratamento de variáveis exógenas. Incorporá-las ao modelo exige sincronização temporal, normalização adequada e tratamento de defasagens temporais. Em muitos casos, a variabilidade de uma variável exógena não está alinhada com a periodicidade da série endógena, o que exige técnicas como interpolação, agregação temporal ou decomposição para capturar componentes relevantes. A inclusão adequada dessas variáveis geralmente eleva substancialmente a precisão, especialmente em sistemas afetados por clima, carga, uso humano ou sazonalidades complexas.
Ao lado disso, torna-se indispensável definir um bom método de validação temporal, uma vez que os dados são sequenciais. Técnicas tradicionais de validação cruzada não se aplicam diretamente; em seu lugar, utiliza-se o método walk-forward. Nele, divide-se a série em blocos: uma parte para treino, seguida de uma janela de teste. Em cada passo, o bloco de teste avança, simulando previsões no mundo real. Essa estratégia revela como o modelo se comportaria caso estivesse operando em produção.
Finalmente, há as estratégias de pós-processamento, como reconversão para escalas originais, reintegração de modelos ARIMA, recombinação de componentes sazonais e correção de viés. Em aplicações de larga escala, é comum a utilização de comitês de modelos (ensembles), onde previsões de diferentes modelos são combinadas para melhorar a robustez. Modelos como Granite TTM podem ser usados diretamente, mas muitas equipes combinam previsões do tipo: ARIMA + LSTM + Transformer, obtendo um conjunto mais estável frente a variações extremas.
Com esse conjunto de estratégias — seleção de janela, escolha de horizonte, integração de variáveis, validação e pós-processamento — torna-se possível transformar qualquer modelo, simples ou avançado, em previsões operacionais confiáveis. No capítulo seguinte, discutiremos como interpretar essas previsões e como avaliar rigorosamente sua qualidade em diferentes cenários.
7 — Técnicas de Avaliação e Interpretação das Previsões
Uma previsão só tem valor quando pode ser avaliada com clareza e interpretada corretamente. Em aplicações reais – seja previsão de consumo energético, demanda de estoque, degradação de equipamentos, fluxo de usuários ou séries financeiras – a capacidade de medir a precisão do modelo é o que determina sua utilidade. Mais do que gerar números, um sistema de previsão deve fornecer previsões compreensíveis, confiáveis e alinhadas ao comportamento real do fenômeno. Este capítulo explora as métricas, métodos de avaliação e estratégias de interpretação que permitem validar previsões de forma rigorosa.
A avaliação começa pela escolha das métricas de erro, que quantificam o desvio entre previsões e valores reais. Entre as mais utilizadas está o MAE (Mean Absolute Error), que mede o erro médio absoluto e é de fácil interpretação. Outra métrica importante é o RMSE (Root Mean Square Error), que penaliza erros maiores, sendo ideal para fenômenos sensíveis a grandes desvios. Já o MAPE (Mean Absolute Percentage Error) expressa o erro em porcentagem, o que facilita a comunicação com gestores e equipes não técnicas. Em cenários industriais, também é comum o uso de métricas personalizadas associadas a custo, como penalização por superestimativa ou subestimativa, especialmente quando a previsão influencia processos logísticos ou energéticos.
Além das métricas pontuais, é essencial utilizar técnicas adequadas de validação temporal. O método walk-forward validation é o mais fiel ao ambiente operacional, pois simula o uso real do modelo ao deslocar progressivamente a janela de teste para frente no tempo. Outra abordagem é a divisão da série em múltiplos blocos temporais (time-series cross-validation), onde cada bloco serve como teste em diferentes momentos históricos. Essa estratégia permite avaliar a estabilidade do modelo frente a mudanças estruturais, sazonais ou eventos excepcionais.
Um aspecto frequentemente negligenciado é a interpretação da previsão. Em modelos clássicos, como ARIMA, a interpretação é relativamente direta: coeficientes autorregressivos indicam impacto de lags passados, e os termos sazonais mostram periodicidades relevantes. Já em modelos de Deep Learning e Transformers, a interpretação é menos intuitiva. Para contornar isso, empregam-se técnicas como análise de importância de variáveis (feature importance), mapas de atenção (attention maps) e decomposição das contribuições de cada janela temporal. Em modelos de larga escala como o Granite TTM, os mapas de atenção revelam quais períodos temporais foram mais relevantes para cada previsão, permitindo explicar o raciocínio matemático interno do modelo.
Outro elemento crucial é a detecção de limitações e anomalias nas previsões. Em séries muito ruidosas, mesmo modelos avançados podem gerar previsões instáveis. Por isso, técnicas de análise residual são indispensáveis: ao examinar o resíduo (valor real – previsão), podemos identificar se o modelo está capturando adequadamente a estrutura temporal. Um resíduo aleatório é sinal de bom ajuste; já resíduos sistemáticos indicam padrões não capturados, sugerindo a necessidade de variáveis exógenas adicionais, aumento da janela ou troca de modelo.
Por fim, é relevante considerar o uso de intervalos de confiança. Previsões determinísticas fornecem apenas um valor central, mas fenômenos reais carregam incerteza. Métodos estatísticos como ARIMA fornecem intervalos naturalmente; em modelos neurais, utilizam-se técnicas como dropout estocástico, ensembles e quantile regression para obter previsões probabilísticas. Isso permite que decisões operacionais sejam tomadas com base não apenas no valor previsto, mas também na margem de incerteza associada.
Essas técnicas compõem o núcleo da avaliação moderna de modelos de previsão. No próximo capítulo, vamos explorar aplicações práticas desses conceitos em diferentes setores e contextos, mostrando como combinar variáveis, modelos e estratégias de avaliação para resolver problemas reais de previsão de séries históricas.
8 — Aplicações Práticas e Integração dos Métodos em Ambientes Reais
Depois de compreender variáveis, técnicas matemáticas, modelos modernos e estratégias de obtenção e avaliação das previsões, o passo natural é observar como esses elementos se combinam em aplicações reais. Em cenários industriais, financeiros, energéticos e IoT, a previsão temporal é um componente crítico para tomada de decisão, otimização de recursos e mitigação de riscos. Este capítulo apresenta exemplos práticos que evidenciam como os conceitos anteriores se articulam para resolver problemas complexos em diferentes domínios.
No setor energético, a previsão de carga elétrica combina variáveis endógenas — como histórico de consumo — com variáveis exógenas, como temperatura, umidade e indicadores econômicos. Métodos clássicos como ARIMA e Holt-Winters ainda são amplamente usados para horizontes curtos, mas modelos modernos vêm ganhando espaço devido à complexidade crescente das redes elétricas. Modelos como LSTM, TCN e Transformers são capazes de incorporar múltiplas escalas temporais e variáveis simultaneamente, melhorando a previsão em períodos de alta volatilidade. Em aplicações de grande escala, o Granite TTM destaca-se por integrar centenas de séries correlatas ao mesmo tempo, fornecendo previsões robustas mesmo em condições de mudanças abruptas no comportamento da rede.
Em ambientes industriais e IoT, a previsão temporal é fundamental para manutenção preditiva. Motores, bombas, transformadores, esteiras e sistemas eletrônicos geram séries de temperatura, vibração, corrente elétrica e pressão. O objetivo é prever falhas antes que ocorram. O uso de modelos multivariados, que integram variáveis endógenas (como histórico de vibração) e exógenas (como carga aplicada), permite antecipar padrões de degradação. Em séries altamente ruidosas, decomposições STL e modelos ARIMAX podem servir como filtros estruturais, enquanto redes neurais — especialmente Transformers — capturam relações não lineares complexas entre sensores. Em projetos mais recentes, modelos como TimeGPT e Granite TTM vêm sendo usados como “fundação preditiva” sobre a qual modelos menores, específicos ao equipamento, são refinados.
No varejo e e-commerce, a previsão de demanda utiliza séries como histórico de vendas, dados de promoções, sazonalidades (como feriados), clima e comportamento de navegação dos usuários. Técnicas de regressão multivariada, Prophet, ARIMAX e modelos neurais são aplicados conforme o horizonte de previsão e disponibilidade de dados. O desafio é integrar componentes de curto prazo — como oscilações diárias — com tendências anuais e variáveis exógenas de campanhas de marketing. Modelos de larga escala, quando bem ajustados, conseguem generalizar padrões de comportamento e reduzir drasticamente rupturas de estoque.
Na telecomunicação e redes de computadores, prever tráfego e congestionamento requer lidar com séries altamente voláteis. Técnicas como modelos autorregressivos, TCN e Transformers temporais são empregadas para antecipar períodos de pico. A integração de variáveis exógenas — como eventos esportivos, horário do dia ou atualizações de software — é essencial para capturar mudanças abruptas. Modelos avançados são capazes de prever congestionamentos com antecedência suficiente para reconfigurar rotas e ajustar políticas de QoS (Qualidade de Serviço).
Na área de finanças, séries temporais apresentam ruído elevado e dinâmicas complexas, tornando a aplicação de métodos clássicos limitada. Modelos LSTM e Transformers, treinados para captar dependências longas e interações não lineares, têm se mostrado promissores, especialmente quando combinados com variáveis exógenas macroeconômicas. Em escala global, modelos fundacionais como Granite TTM vêm sendo usados como ferramentas auxiliares para análise de risco, previsão de volatilidade e identificação de correlações ocultas.
Essas aplicações mostram que a previsão de séries históricas não é apenas um exercício matemático, mas um componente estruturante em diversos sistemas modernos. Nos próximos capítulos, veremos como integrar tudo isso em pipelines completos de previsão, automatizar etapas e alinhar metodologias com boas práticas de engenharia de dados e implementação.
9 — Construção de Pipelines de Previsão: Da Aquisição de Dados à Entrega dos Resultados
Para que modelos de previsão funcionem de forma confiável no mundo real, é necessário mais do que um algoritmo bem escolhido. É preciso construir um pipeline completo, capaz de tratar dados brutos, executar o modelo, validar resultados, registrar histórico e entregar previsões de maneira automatizada e estável. Esse pipeline, muitas vezes implementado em ambientes de produção com IoT, sistemas industriais, bancos de dados e microsserviços, é tão importante quanto o próprio modelo. Este capítulo aborda cada etapa desse fluxo, destacando boas práticas usadas em engenharia de software, ciência de dados e sistemas embarcados.
O ciclo começa pela aquisição dos dados. Em sistemas industriais e IoT, isso pode envolver sensores físicos, microcontroladores, brokers MQTT, filas Kafka ou APIs de telemetria. A consistência temporal é fundamental: timestamps devem ser precisos, e a frequência de coleta deve ser estável. A partir daí, inicia-se o processo de pré-processamento, que envolve limpeza, interpolação de faltas, remoção de outliers, agregação temporal e transformação das variáveis. Para modelos neurais e Transformers, aplica-se também normalização ou padronização dos valores. Em pipelines mais complexos, essa etapa é automatizada através de scripts ou jobs contínuos executados em servidores, datalakes ou dispositivos embarcados.
A segunda camada é o tratamento estrutural da série, onde se definem janelas temporais, horizontes de previsão e integração de variáveis exógenas. É também aqui que modelos pré-treinados de larga escala podem ser incorporados. Por exemplo, o Granite TTM pode ser usado como um backbone capaz de extrair representações temporais enriquecidas, sobre as quais modelos menores realizam previsões específicas do domínio. Essa abordagem híbrida reduz a necessidade de treinar modelos do zero e permite adaptações rápidas ao comportamento do sistema.
A etapa seguinte consiste na execução do modelo, que pode ocorrer de maneira agendada (batch) ou contínua (streaming). Previsões em lote são adequadas para demandas diárias ou semanais — como planejamento energético ou logística de estoque — enquanto previsões em tempo real são essenciais para telecomunicações, redes e manutenção preditiva. Em sistemas mais sensíveis, técnicas como quantile regression ou modelos probabilísticos fornecem intervalos de confiança junto com a previsão, ajudando na tomada de decisão.
Após a obtenção dos resultados, é necessário realizar a validação operacional. Enquanto durante o treinamento utilizamos walk-forward validation e métricas como MAE e RMSE, no ambiente produtivo utiliza-se o monitoramento contínuo da performance. Isso envolve comparar previsões com valores reais ao longo do tempo, detectar drift na distribuição dos dados e identificar deterioração de desempenho. Em pipelines robustos, mecanismos de retreinamento automático são acionados quando métricas caem abaixo de limites predefinidos.
A última fase é a entrega e consumo das previsões, que pode ocorrer via dashboards, APIs, relatórios, sistemas de alerta ou integração com softwares de automação. Em ambientes industriais, previsões podem ser transmitidas diretamente para CLPs, microcontroladores ou sistemas SCADA. Em contextos de business intelligence, dashboards analíticos permitem visualizar tendências e incertezas associadas a cada previsão. Em aplicações de larga escala, o pipeline pode alimentar outros módulos, como otimização, detecção de anomalias ou agentes de tomada de decisão.
Esse ciclo completo transforma modelos matemáticos em ferramentas reais de apoio operacional e estratégico. Sem um pipeline bem estruturado, até mesmo modelos avançados como Transformers temporais e Granite TTM tornam-se ineficazes. No próximo capítulo, concluiremos o artigo apresentando uma síntese dos pontos principais e orientações para escolha do modelo ideal em diferentes cenários.
10 — Síntese, Recomendações e Boas Práticas na Previsão de Séries Históricas
Ao longo deste artigo, percorremos o caminho completo da previsão de séries históricas: desde os fundamentos conceituais até os modelos mais avançados e a implementação em pipelines de produção. Este capítulo final sintetiza os principais aprendizados e apresenta recomendações práticas para quem deseja aplicar essas técnicas de forma eficiente e robusta em cenários reais.
O primeiro ponto essencial é o domínio das variáveis. Saber identificar variáveis endógenas e exógenas, distinguir variáveis contínuas e discretas, entender escalas e tipos de medição é a base para qualquer modelagem. Modelos estatísticos simples dependem fortemente de estacionaridade e estrutura primária da série, enquanto arquiteturas modernas podem absorver maior complexidade e heterogeneidade. Independentemente da técnica adotada, a preparação dos dados determina grande parte da precisão do modelo.
Outra síntese importante refere-se ao equilíbrio entre modelos clássicos e modernos. Métodos tradicionais como ARIMA, Holt-Winters, STL e VAR continuam fundamentais graças à sua interpretabilidade e ao baixo custo computacional. Em muitas aplicações, especialmente de curto prazo, esses modelos ainda são a melhor escolha. Já modelos neurais e Transformers oferecem vantagens significativas em séries com padrões não lineares, múltiplas escalas temporais ou grande volume de variáveis exógenas. Modelos fundacionais de larga escala, como o Granite TTM, ampliam esse alcance ao incorporar conhecimento aprendido em enormes conjuntos de dados temporais, tornando-se poderosos para domínios complexos ou com dados escassos.
A terceira lição é a importância das estratégias de previsão, que incluem definição de janelas temporais, horizonte, normalização, escolha da técnica de validação e tratamento das variáveis externas. Em pipelines profissionais, essas escolhas são mais determinantes do que o modelo em si. Modelos excelentes podem falhar quando alimentados com janelas inadequadas, variáveis mal sincronizadas ou dados não estacionários.
Também vimos que a avaliação das previsões não deve se limitar a métricas numéricas. Interpretabilidade, análise residual, intervalos de confiança e monitoramento contínuo são essenciais para detectar degradação ao longo do tempo. Em sistemas reais, drifts de dados costumam ocorrer, seja por mudança de comportamento dos usuários, seja por alterações em processos industriais, sazonalidades excepcionais ou eventos externos. Ter mecanismos de alarme e retreinamento automático é indispensável para longevidade do sistema de previsão.
Por fim, destacamos a construção de um pipeline completo, incluindo aquisição, pré-processamento, modelagem, validação, monitoração e entrega. Sem esse arcabouço, mesmo o melhor modelo não se sustenta em produção. O pipeline deve ser modular, observável e adaptável, permitindo substituição de modelos, inclusão de novas variáveis e ajustes automáticos conforme o comportamento dos dados evolui.
Em síntese, a previsão de séries históricas é uma disciplina estratégica que combina matemática, estatística, engenharia de dados e inteligência artificial. Seu poder reside na capacidade de antecipar cenários, orientar decisões e reduzir incertezas em sistemas complexos. Ao integrar fundamentos sólidos, técnicas modernas e boas práticas de engenharia, é possível construir soluções preditivas confiáveis tanto para pequenas aplicações quanto para sistemas de larga escala operando em setores críticos da economia.