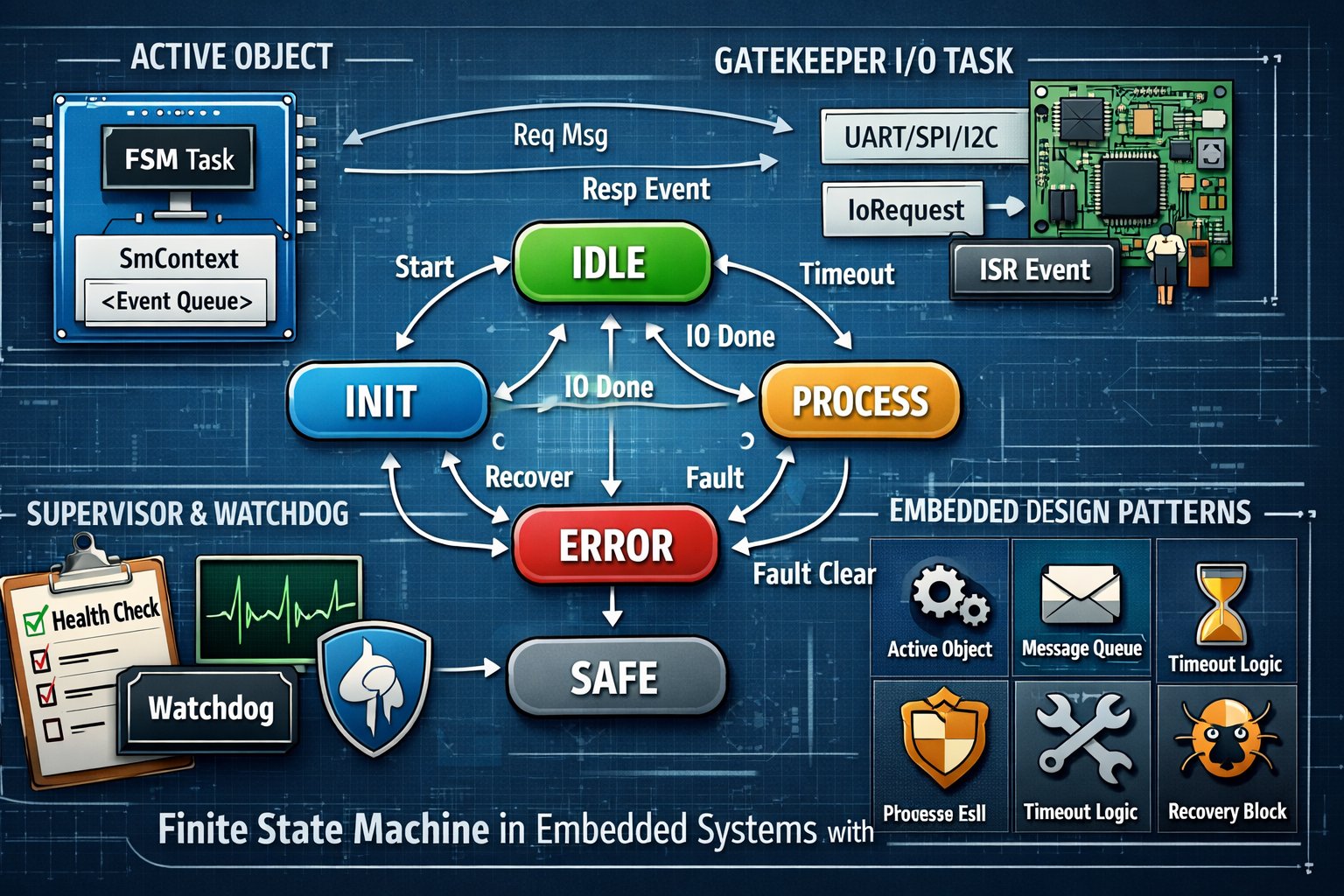
Tornando “produção”: entry-actions, correlação request/response e boas vs más escolhas
O exemplo anterior já funciona, mas ainda tem três pontos que em firmware real viram dor de cabeça se não forem arrumados: (1) ações de entrada misturadas com lógica de evento (fica difícil garantir que algo roda “uma vez”); (2) correlação entre requisição e resposta (você precisa ter certeza que o IO_DONE é daquele request); (3) boas vs más escolhas para não deixar o design degradar para um “superloop com filas”.
5.1 Entry-actions: rodar “uma vez” ao entrar no estado
No código anterior, ST_CYCLE_START sempre executa a ação de pedir I/O e já sai. Isso é ok, mas quando estados ficam mais ricos (ex.: INIT com várias etapas), você quer separar:
- “Entrei no estado X” → executar ações de entrada uma vez.
- “Estou no estado X e chegou evento Y” → executar reação.
O jeito mais simples em C é guardar o estado anterior e disparar entry-actions quando prev != current. No contexto:
typedef struct {
SmState st;
SmState prev;
/* ... resto ... */
} SmContext;
E no loop:
if (ctx.prev != ctx.st) {
sm_on_entry(&ctx); /* ações de entrada */
ctx.prev = ctx.st;
}
sm_on_event(&ctx, &ev); /* reação ao evento */
Isso evita bugs clássicos tipo “pedi I/O duas vezes porque recebi dois EVT_TICK”.
Um sm_on_entry() mínimo:
static void sm_on_entry(SmContext *ctx) {
switch (ctx->st) {
case ST_BOOT:
ctx->retry_count = 0;
ctx->last_error = ERR_NONE;
ctx->io_deadline_tick = 0;
break;
case ST_CYCLE_START:
ctx->cycle_count++;
ctx->pending_req_id++; /* gera novo ID */
sm_request_io_read(ctx); /* envia request e arma deadline */
sm_enter_state(ctx, ST_WAIT_IO);
break;
case ST_RECOVER:
ctx->retry_count++;
sm_backoff_delay(ctx->retry_count);
/* em produção: reset específico (UART flush, SPI reinit, power-cycle, etc.) */
{
IoRequest r = {.type = IOREQ_RESET_BUS, .req_id = ctx->pending_req_id + 1};
(void)io_send_req(&r, pdMS_TO_TICKS(5));
}
sm_enter_state(ctx, ST_CYCLE_START);
break;
default:
break;
}
}
E o sm_on_event() fica mais “limpo” e previsível: ele não faz ações que deveriam rodar “uma vez”.
5.2 Correlação por req_id: evitando consumir resposta errada
Em sistema real, eventos podem chegar atrasados (DMA terminou tarde, interrupção atrasou, periférico engasgou). Se você não correlacionar, pode acontecer:
- Você manda request A (
req_id=10) - Timeout, você tenta de novo, manda request B (
req_id=11) - Resposta do A chega atrasada → você processa como se fosse do B → bug fantasma
Como corrigir: incluir req_id no payload do evento de IO e validar:
- Adicione
req_idno evento:
typedef struct {
SmEventType type;
uint32_t timestamp_ms;
union {
struct {
uint32_t req_id;
uint8_t data[8];
uint8_t len;
} io;
struct { SmError cause; } fault;
} u;
} SmEvent;
- Faça a IO task responder com
req_id:
ev.type = EVT_IO_DONE;
ev.u.io.req_id = req.req_id;
- No
ST_WAIT_IO, valide:
if (ev->type == EVT_IO_DONE) {
if (ev->u.io.req_id != ctx->pending_req_id) {
/* Resposta atrasada/fora de ordem: descarta ou loga */
break;
}
ctx->io_deadline_tick = 0;
sm_enter_state(ctx, ST_PROCESS);
}
Isso sozinho elimina uma classe enorme de falhas “intermitentes”.
5.3 Boa escolha vs má escolha (na prática)
Má escolha 1: “Delay como controle de fluxo”
- Exemplo ruim: em
ST_WAIT_IOvocê fazvTaskDelay(50ms)esperando o hardware “dar tempo”. - Problema: você congela a lógica, perde eventos, e não tem como provar deadline.
- Boa escolha: deadline + evento (
EVT_IO_DONE/FAIL) +EVT_TIMEOUTinterno.
Má escolha 2: Variável global “flag de pronto”
- Exemplo ruim: IO task escreve
volatile bool io_done;e a FSM fica testando. - Problema: corrida (quando zera? quem zera?), falta de payload, difícil debugar.
- Boa escolha: fila com mensagem tipada, com
req_id, status e dados.
Má escolha 3: Callbacks reentrantes chamando a FSM
- Exemplo ruim: ISR ou callback do driver chama
sm_step()direto. - Problema: reentrância, stack diferente, prioridade diferente, e você quebra “run-to-completion”.
- Boa escolha: ISR só empacota evento e manda para fila (
xQueueSendFromISR), FSM processa em task.
Má escolha 4: “Switch gigante” sem disciplina
- Exemplo ruim: um
switch(state)com 400 linhas e efeitos colaterais espalhados. - Problema: entry-actions duplicadas, transições implícitas, regressões fáceis.
- Boa escolha:
on_entry + on_event, ou tabela de transições, e “um lugar só” para cada decisão.
5.4 Padrões explícitos que estamos aplicando aqui
- Active Object: FSM como task única dona do estado interno.
- State Pattern (C pragmático): handlers por estado/evento, ou separação entry/event.
- Reactor / Event Loop: processamento dirigido por eventos.
- Error Containment: zona de erro e recuperação que impede “propagação” de falha.
- Time Budgeting (deadline): timeout é parte do contrato do estado.