Checklist prático, métricas de campo e extensões naturais da FSM
Para fechar o artigo de forma útil no dia a dia, esta seção é intencionalmente operacional. É o tipo de material que você imprime ou deixa no repositório para revisar antes de subir firmware em produção.
8.1 Checklist de boas práticas (FSM + FreeRTOS)
Arquitetura
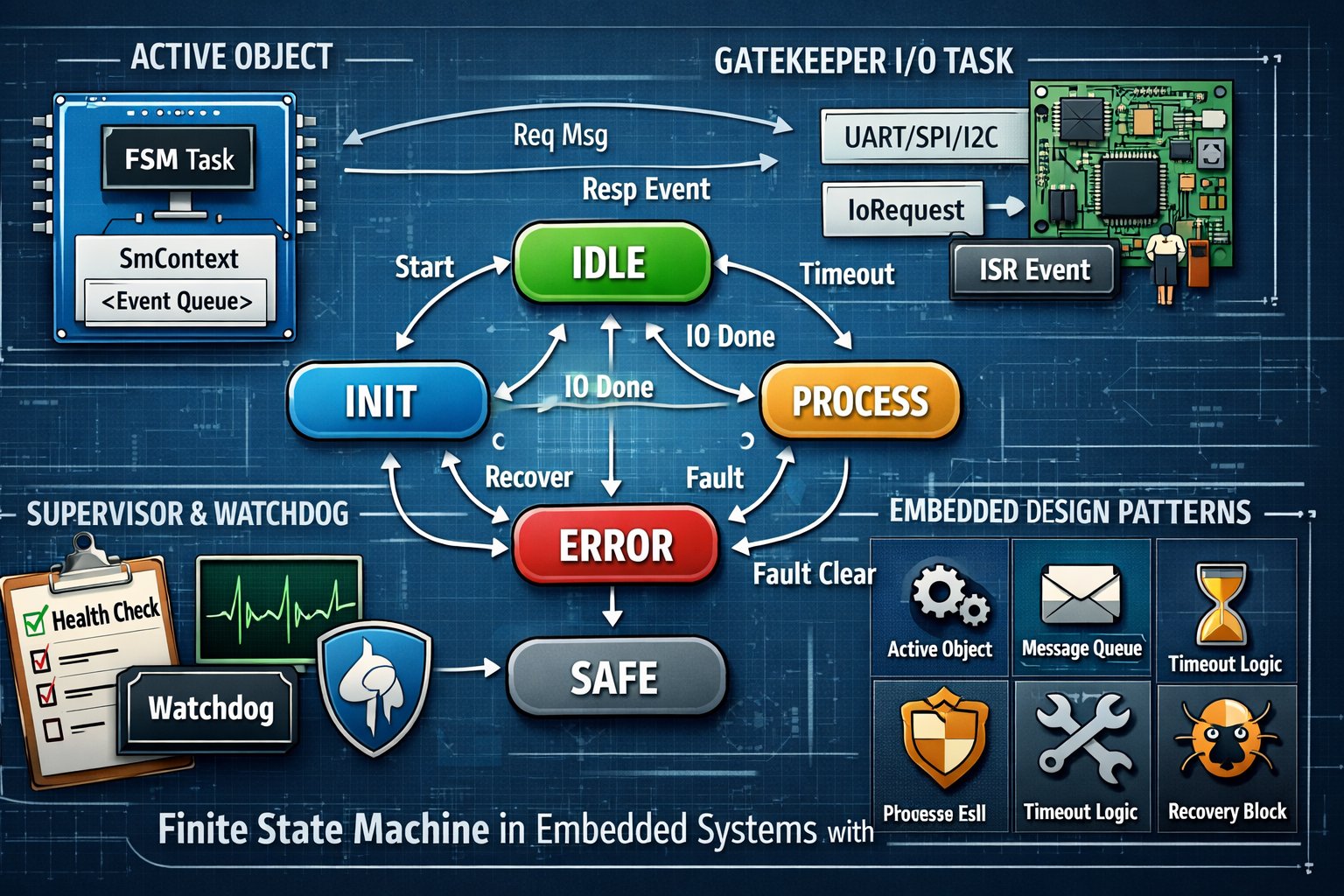
- Cada FSM é dona exclusiva do seu estado interno (Active Object).
- Comunicação entre tasks somente por fila/notificação, nunca por variável global solta.
- Um periférico → um Gatekeeper. Nunca dois donos do mesmo hardware.
- Estados e eventos são enumerados e documentados (sem “números mágicos”).
Estados
- Todo estado tem responsabilidade clara.
- Ações que devem rodar uma única vez ficam em entry-actions.
- Não existe “estado implícito” escondido em flags.
- Existe sempre um estado seguro (
SAFE,FAIL,DEGRADED).
Eventos
- Eventos são tipados (enum), não booleanos genéricos.
- Eventos de I/O carregam payload + req_id.
- Timeouts são eventos explícitos, não delays soltos.
Timeouts e recuperação
- Todo estado que espera algo externo tem deadline.
- Retentativas têm limite e, preferencialmente, backoff.
- Falha persistente leva a degradação controlada, não a looping infinito.
FreeRTOS
- FSM nunca roda em ISR.
- ISR só empacota evento e envia com
xQueueSendFromISR. - Prioridade da FSM > prioridade do Gatekeeper (na maioria dos casos).
- Fila tem tamanho dimensionado para o pior caso realista.
8.2 O que medir e logar (para depuração em campo)
FSM sem observabilidade vira “caixa preta”. Algumas métricas simples resolvem 80% dos problemas:
- Estado atual (
st) — exportável via debug, log ou telemetria. - Último erro (
last_error) — classificado, não string solta. - cycle_count — prova de que o sistema está avançando.
- retry_count — indicador de degradação iminente.
- tempo por estado — opcional, mas poderoso (profiling em campo).
- eventos descartados (req_id errado, fila cheia).
Em sistemas com log limitado:
- registre apenas transições de estado,
- registre entrada em ERROR/SAFE,
- registre reset lógico.
Isso já permite reconstruir o comportamento pós-mortem.
8.3 Watchdog lógico: como integrar de forma correta
Uma estratégia simples e eficaz:
- A FSM incrementa um heartbeat lógico (ex.:
cycle_count) apenas quando completa um ciclo saudável. - Uma task de monitoramento (ou o Supervisor):
- verifica se
cycle_countavançou nos últimos T segundos, - verifica se não ficou presa em
WAIT_IOouRECOVERalém do aceitável, - só então alimenta o watchdog de hardware.
- verifica se
Resultado:
O watchdog passa a representar saúde funcional, não só “CPU viva”.
8.4 Extensões naturais (quando o sistema crescer)
Tabela de transições
- Substitui
switchgrande por dados. - Facilita revisão em equipe e testes automatizados.
- Ideal quando estados/eventos passam de ~10×10.
HSM — Hierarchical State Machine
- Estados “pais” com comportamento comum (ex.:
OPERATIONAL). - Reduz duplicação quando vários estados compartilham regras.
- Muito útil para protocolos e sistemas de comunicação.
Software Timers do FreeRTOS
- Timeouts podem virar eventos gerados por timer.
- Remove checagem manual de deadline no loop.
- Bom quando há muitos timeouts independentes.
Supervisor global
- Coordena várias FSMs.
- Implementa modos globais: BOOT, NORMAL, DEGRADED, SAFE.
- Excelente para produtos complexos (rede + sensores + atuadores).
8.5 Ideia-chave para levar consigo
Máquina de Estados não é um detalhe de implementação.
É uma decisão arquitetural.
Quando bem feita:
- o comportamento fica previsível,
- falhas ficam contidas,
- e o sistema se explica sozinho ao ser lido.
Quando mal feita:
- vira um amontoado de
if,delaye flags, - impossível de provar, depurar ou manter.
O exemplo com FreeRTOS e duas threads que construímos aqui não é “acadêmico”: ele é um esqueleto reutilizável para protocolos, controle, comunicação e supervisão em sistemas embarcados reais.
Antes de encerrar, vale amarrar o artigo do ponto de vista editorial e técnico. O conteúdo que construímos não é um “tutorial isolado”, mas um padrão arquitetural reutilizável para firmware profissional. Ele se posiciona entre dois mundos: simples demais para ser apenas um superloop, e disciplinado o suficiente para escalar sem virar um RTOS “caótico”.
Síntese técnica do artigo
O artigo demonstrou que uma Máquina de Estados em sistemas embarcados não deve ser tratada como um detalhe algorítmico, mas como um mecanismo central de governança do comportamento do sistema. Ao usar o FreeRTOS com duas threads bem delimitadas, mostramos como separar responsabilidades de forma clara: uma task dona da lógica (FSM como Active Object) e outra task dona do hardware (Gatekeeper). Essa separação reduz acoplamento, evita condições de corrida e torna o sistema previsível.
A FSM apresentada é cíclica porque o sistema nunca “termina”: ele opera continuamente, ciclo após ciclo. E é recuperável porque falhas não interrompem o fluxo de forma caótica; elas são absorvidas por estados explícitos de erro e recuperação, com limites, backoff e fallback para um estado seguro. Esse desenho reflete como sistemas reais precisam se comportar em campo, onde resetar o microcontrolador nem sempre é aceitável.
Do ponto de vista de padrões de projeto, o texto mostrou como conceitos clássicos — Active Object, State Pattern, Gatekeeper, Supervisor e Error Containment — não são abstrações acadêmicas, mas ferramentas práticas que se traduzem diretamente em código C legível e auditável. O uso disciplinado de filas, eventos tipados, deadlines e correlação de requisições cria firmware que explica a si mesmo quando alguém o lê meses depois.