Este artigo explica, em profundidade e de forma didática, como o simulador 2D (SDL2) funciona, como o algoritmo de geração de labirintos é implementado e como o planejamento de rota é concebido no projeto rp2040_maze_solver.
O texto referencia funções reais do código, como generate_maze() em simulator/main.cpp, a representação maze::MazeMap em src/core/MazeMap.hpp, a navegação/planejamento em src/core/Navigator.cpp, e a heurística simples em src/core/Learning.hpp.
Visão Geral e Arquitetura
Nesta seção, apresentamos os conceitos centrais: representação do labirinto, geração, percepção (sensores), decisão (planejamento/heurística) e execução (movimento). Essas peças se integram no simulador 2D para permitir inspeção visual, logging e comparação de estratégias.
Componentes do Projeto
- Mapa e célula:
maze::MazeMapemsrc/core/MazeMap.hppdefine uma grade W×H, onde cada célula possui flags de parede:wall_n,wall_e,wall_s,wall_w. - Simulador 2D:
simulator/main.cppusa SDL2 para desenhar grade, paredes e o agente, além de gerar mapas novos (generate_maze()), salvar/carregar arquivos e simular decisões do agente passo a passo. - Navegador/Planejador:
src/core/Navigator.cppcontém a lógica de decisão: heurística (ex.: Right-Hand) e caminho planejado (viaPlanner::bfs_path(map_, start_, goal_)). - Heurística/Aprendizado:
src/core/Learning.hppimplementa pesos de preferência e atualização por recompensa incremental. - Sensores: no simulador, leituras relativas são derivadas do mapa (função utilitária
make_sensor_read()); no hardware,src/hal/IRSensorArray.*lê e filtra sensores IR via ADC do RP2040.
Fluxo de Dados (Mapa, Sensores, Decisão, Movimento)
- Percepção — No simulador, a leitura relativa é sintetizada a partir da célula atual e da orientação absoluta (
heading ∈ {0:N,1:E,2:S,3:W}). Trecho simplificado desimulator/main.cpp(make_sensor_read):
static maze::SensorRead make_sensor_read(const MazeMap& m, Point cell, uint8_t heading) {
maze::SensorRead sr{};
const Cell& c = m.at(cell.x, cell.y);
auto abs_left = (heading + 3) & 3;
auto abs_front = heading;
auto abs_right = (heading + 1) & 3;
auto is_free = [&](int absdir){
switch (absdir) {
case 0: return !c.wall_n; case 1: return !c.wall_e;
case 2: return !c.wall_s; default: return !c.wall_w;
}
};
sr.left_free = is_free(abs_left);
sr.front_free = is_free(abs_front);
sr.right_free = is_free(abs_right);
return sr;
}
- Observação de paredes: o
Navigatorconverte leitura relativa em marcação absoluta no mapa:
void Navigator::observeCellWalls(Point cell, const SensorRead& sr, uint8_t heading) {
auto set_dir = [&](char dir, bool free_flag){ map_.set_wall(cell.x, cell.y, dir, !free_flag); };
const char abs_dirs[4] = {'N','E','S','W'};
auto rel_to_abs = [&](int rel){
int base = (int)heading;
int d = (rel==0) ? (base + 3) & 3 : (rel==1) ? base : (base + 1) & 3;
return abs_dirs[d];
};
set_dir(rel_to_abs(0), sr.left_free);
set_dir(rel_to_abs(1), sr.front_free);
set_dir(rel_to_abs(2), sr.right_free);
}
- Decisão — Existem dois caminhos: heurístico e planejado.
- Heurístico Right-Hand (simplificado):
Decision Navigator::decide(const SensorRead& sr) {
Decision d{};
if (strategy_ == Strategy::RightHand) {
if (sr.right_free) d.action = Action::Right;
else if (sr.front_free) d.action = Action::Forward;
else if (sr.left_free) d.action = Action::Left;
else d.action = Action::Back;
}
d.score = score_for(d.action, sr);
return d;
}
- Planejado: quando há um plano (caminho) válido,
decidePlanned()transforma a direção absoluta desejada em ação relativa à orientação atual, com desempate por “células menos visitadas” e alinhamento ao plano.
- Execução — A ação
Left/Right/Backaltera a orientação;Forwardmove a posição conformeheading(videapply_move()emsimulator/main.cpp). O simulador verifica colisão antes de avançar.
Convenções: sistema de coordenadas, direções e cabeçalho
- Coordenadas:
Point{x,y}onde x cresce para Leste e y cresce para Sul (linha-major). A célula vizinha a Norte temy-1, a Lestex+1, a Suly+1e a Oestex-1. - Direções absolutas:
0=N, 1=E, 2=S, 3=W. - Ações relativas:
Left,Front/Forward,Right,Backsão definidas em relação aoheadingatual. - Rotação modular (matemática):
Seja h ∈ {0,1,2,3}. Então
- left(h) = (h + 3) mod 4
- right(h) = (h + 1) mod 4
- back(h) = (h + 2) mod 4
Essas transformações aparecem no código, e são uma forma eficiente de operar com direções discretas (grupo cíclico Z4).
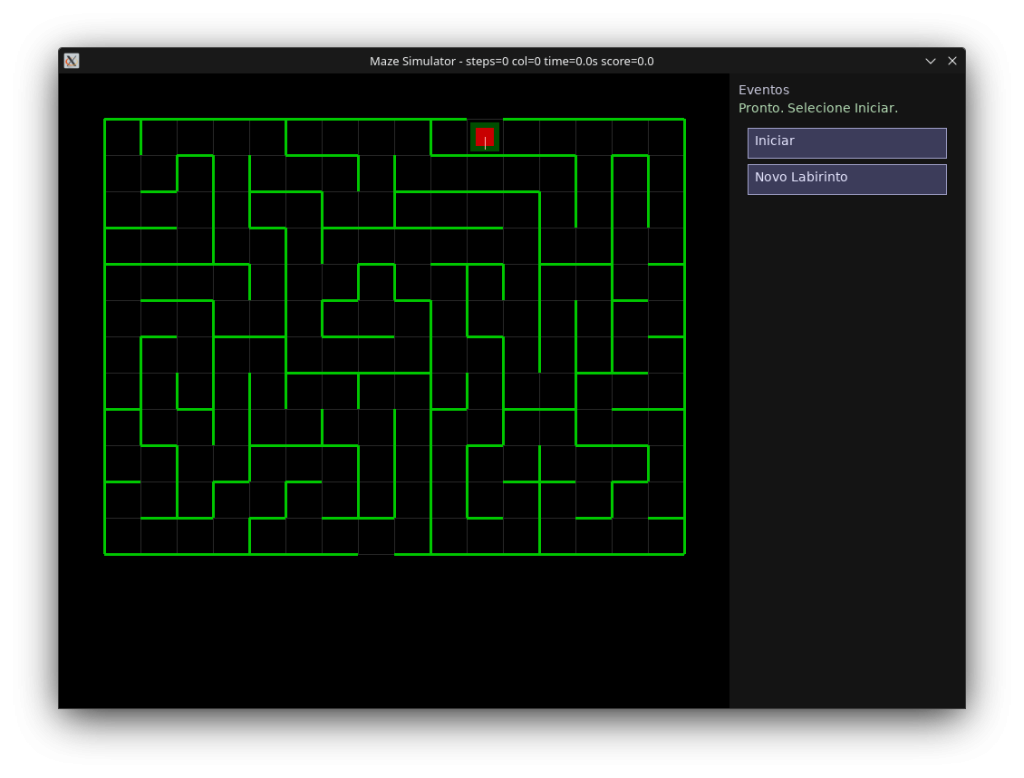
Representação do Labirinto (MazeMap)
Esta seção descreve a estrutura de dados central que representa o labirinto em grade, como as paredes são mantidas de forma bidirecional e quais invariantes garantem consistência, além de mostrar a saída ASCII útil para depuração e testes.
Estrutura de célula e paredes bidirecionais
- Em
src/core/MazeMap.hpp, cada célula é ummaze::Cellcom quatro flags:
struct Cell {
bool wall_n{false}; <em>// Parede ao norte</em>
bool wall_e{false}; <em>// Parede ao leste</em>
bool wall_s{false}; <em>// Parede ao sul</em>
bool wall_w{false}; <em>// Parede ao oeste</em>
};
- O mapa é uma grade W×H linearizada (ordem linha-major) em
maze::MazeMap. - O método-chave é
set_wall(x,y,dir,present), que atualiza a parede da célula (x,y) e a parede oposta do vizinho, mantendo a bidirecionalidade:
void set_wall(int x, int y, char dir, bool present) {
if (!in_bounds(x,y)) return;
Cell& c = at(x,y);
if (dir=='N') { c.wall_n = present; if (in_bounds(x,y-1)) at(x,y-1).wall_s = present; }
else if (dir=='E') { c.wall_e = present; if (in_bounds(x+1,y)) at(x+1,y).wall_w = present; }
else if (dir=='S') { c.wall_s = present; if (in_bounds(x,y+1)) at(x,y+1).wall_n = present; }
else if (dir=='W') { c.wall_w = present; if (in_bounds(x-1,y)) at(x-1,y).wall_e = present; }
}
Esse design evita “fendas” (gaps) entre células e simplifica a lógica de colisão/visibilidade.
Consistência de paredes e fronteiras
Para toda célula válida (x,y) e seu vizinho na direção dir, valem as invariantes:
- Se
dir='E'e(x+1,y)está emboundsentãowall_e(x,y) == wall_w(x+1,y). - Se
dir='S'e(x,y+1)está emboundsentãowall_s(x,y) == wall_n(x,y+1). - Analogamente para
NeW.
Formalmente, usando notação de pares ordenados e índices válidos:
∀x,y: 0≤x<w, 0≤y<h
in_bounds(x+1,y) ⇒ wall_e(x,y) = wall_w(x+1,y)
in_bounds(x,y+1) ⇒ wall_s(x,y) = wall_n(x,y+1)
Essas invariantes são reforçadas sempre que set_wall() é chamado. Para as fronteiras externas do mapa (bordas), o código só atualiza a célula vizinha se in_bounds(...) for verdadeiro, o que impede acessos inválidos.
Exemplo de uso correto ao “carvar” uma passagem entre células adjacentes (função utilitária carve_between() no simulador):
static void carve_between(MazeMap& m, int x1, int y1, int x2, int y2) {
if (x2 == x1 && y2 == y1-1) { m.set_wall(x1,y1,'N',false); }
else if (x2 == x1+1 && y2 == y1) { m.set_wall(x1,y1,'E',false); }
else if (x2 == x1 && y2 == y1+1) { m.set_wall(x1,y1,'S',false); }
else if (x2 == x1-1 && y2 == y1) { m.set_wall(x1,y1,'W',false); }
}
Note que basta remover a parede de um lado; set_wall() garante a remoção do lado oposto.
Saída ASCII e uso em testes
Para depurar rapidamente a topologia, MazeMap::to_string_ascii() gera um desenho de paredes:
std::string to_string_ascii() const {
std::string out;
out.reserve((w_ * 3 + 2) * (h_ * 2 + 1));
out += ' ';
for (int x = 0; x < w_; ++x) { out += '+'; out += (at(x,0).wall_n ? "--" : " "); }
out += "+\n";
for (int y = 0; y < h_; ++y) {
out += ' ';
for (int x = 0; x < w_; ++x) { out += (at(x,y).wall_w ? '|' : ' '); out += " "; }
out += (at(w_-1,y).wall_e ? "|\n" : " \n");
out += ' ';
for (int x = 0; x < w_; ++x) { out += '+'; out += (at(x,y).wall_s ? "--" : " "); }
out += "+\n";
}
return out;
}
Exemplo didático (2×2) com todas as paredes externas presentes e sem passagens internas:
+--+--+
| | |
+--+--+
| | |
+--+--+
Esse recurso é útil em testes unitários e logs de CI para verificar rapidamente se a geração/edição do mapa está correta, sem depender da visualização SDL.
Geração de Labirintos (DFS Aleatório)
Nesta seção, destrinchamos o gerador de labirintos perfeito implementado em simulator/main.cpp na função generate_maze(MazeMap& m, int W, int H, Point& entrance, Point& goal_cell, uint8_t& entrance_heading).
3Labirintos “perfeitos” e propriedades
- Um labirinto perfeito é um grafo planar em grade com exatamente um caminho simples entre quaisquer duas células alcançáveis. Em termos de teoria dos grafos, as células formam os vértices e as passagens (sem parede entre vizinhos) formam as arestas; o resultado é uma árvore sobre a malha (sem ciclos) — logo, com
N=W·Hvértices eN-1arestas. - Consequências:
- Não há loops; portanto, backtracking é suficiente para explorar o mapa inteiro.
- Entre duas células qualquer, há um único caminho simples.
Algoritmo DFS iterativo com pilha
O código inicializa todas as paredes como presentes e então executa uma busca em profundidade (DFS) iterativa, empilhando células e escolhendo vizinhos não visitados em ordem aleatória para “carvar” passagens. Trechos centrais:
<em>// 1) Marca todas as paredes como presentes</em>
for (int y=0; y<H; ++y) for (int x=0; x<W; ++x) {
m.set_wall(x,y,'N',true);
m.set_wall(x,y,'E',true);
m.set_wall(x,y,'S',true);
m.set_wall(x,y,'W',true);
}
<em>// 2) DFS iterativo para carvar</em>
std::random_device rd; std::mt19937 rng(rd());
int sx = uniform(0,W-1), sy = uniform(0,H-1);
std::vector<uint8_t> vis(W*H, 0);
auto idx = [&](int x,int y){ return y*W + x; };
struct Node{int x,y;};
std::vector<Node> stack;
stack.push_back({sx,sy});
vis[idx(sx,sy)] = 1;
while (!stack.empty()) {
auto [cx, cy] = stack.back();
std::vector<Node> nbrs; <em>// vizinhos não visitados</em>
if (cy>0 && !vis[idx(cx,cy-1)]) nbrs.push_back({cx,cy-1});
if (cx<W-1 && !vis[idx(cx+1,cy)]) nbrs.push_back({cx+1,cy});
if (cy<H-1 && !vis[idx(cx,cy+1)]) nbrs.push_back({cx,cy+1});
if (cx>0 && !vis[idx(cx-1,cy)]) nbrs.push_back({cx-1,cy});
if (!nbrs.empty()) {
std::shuffle(nbrs.begin(), nbrs.end(), rng);
auto [nx, ny] = nbrs.front();
carve_between(m, cx, cy, nx, ny); <em>// remove a parede entre (cx,cy) e (nx,ny)</em>
vis[idx(nx,ny)] = 1;
stack.push_back({nx,ny});
} else {
stack.pop_back(); <em>// backtrack</em>
}
}
Onde carve_between() mapeia o deslocamento (N/E/S/W) e chama m.set_wall(..., false), garantindo consistência bidirecional (Seção 2):
static void carve_between(MazeMap& m, int x1, int y1, int x2, int y2) {
if (x2 == x1 && y2 == y1-1) { m.set_wall(x1,y1,'N',false); }
else if (x2 == x1+1 && y2 == y1) { m.set_wall(x1,y1,'E',false); }
else if (x2 == x1 && y2 == y1+1) { m.set_wall(x1,y1,'S',false); }
else if (x2 == x1-1 && y2 == y1) { m.set_wall(x1,y1,'W',false); }
}
Propriedades do DFS:
- A estrutura de pilha induz uma “caminhada profunda” até ficar sem vizinhos não visitados; então retorna (backtrack) e tenta novos ramos.
- Como cada aresta é “carvada” quando visita um vizinho novo, o resultado final é uma árvore que conecta todas as células — um labirinto perfeito.
Complexidade:
- Tempo: O(W·H), pois cada célula é visitada exatamente uma vez; cada aresta potencial é inspecionada O(1) vezes.
- Espaço: O(W·H) para o vetor de visitados e até O(W·H) para a pilha no pior caso de um caminho serpenteante.
Escolha de entrada/saída e orientação inicial
Após carvar a malha interna, o gerador escolhe aleatoriamente um par de bordas opostas e abre uma parede externa para criar entrada e saída, além de definir a orientação inicial (entrance_heading):
std::uniform_int_distribution<int> side_dist(0, 1);
if (side_dist(rng) == 0) {
<em>// Entrada oeste (x=0), saída leste (x=W-1)</em>
int ey = dy(rng), oy = dy(rng);
entrance = {0, ey};
goal_cell = {W-1, oy};
m.set_wall(entrance.x, entrance.y, 'W', false);
m.set_wall(goal_cell.x, goal_cell.y, 'E', false);
entrance_heading = 1; <em>// Leste</em>
} else {
<em>// Entrada norte (y=0), saída sul (y=H-1)</em>
int ex = dx(rng), ox = dx(rng);
entrance = {ex, 0};
goal_cell = {ox, H-1};
m.set_wall(entrance.x, entrance.y, 'N', false);
m.set_wall(goal_cell.x, goal_cell.y, 'S', false);
entrance_heading = 2; <em>// Sul</em>
}
Observações:
- A abertura na borda externa cria a conexão do interior do labirinto com “fora do mundo”.
- A orientação inicial é definida coerente com a borda aberta: se a entrada está no oeste, o agente inicia virado para o leste (
heading=1), e assim por diante.
Aleatoriedade, reprodutibilidade e variação
- O uso de
std::mt19937comstd::random_devicegera sementes de entropia do SO. Para reprodutibilidade, é possível trocar a semente por um valor fixo, por exemplo:
std::mt19937 rng(123456u); <em>// semente fixa para repetir o mesmo labirinto</em>
- Diferentes políticas de escolha do próximo vizinho (por exemplo, ordem fixa em vez de
shuffle) produzem famílias distintas de labirintos quanto a “linearidade” e “entropia visual”. Oshuffletende a produzir passagens mais imprevisíveis. - A topologia resultante influencia estratégias de navegação: em árvores com longos corredores, heurísticas “right-hand” tendem a avançar mais; em regiões ramificadas, backtracking ocorre com maior frequência.
Simulador SDL2: Visualização e Interação
Nesta seção documentamos as rotinas de renderização e a interface do simulador 2D em simulator/main.cpp, incluindo desenho do labirinto, do agente, rastro de visita, loop principal de eventos, painel lateral, botões, e a persistência de arquivos .maze, .plan e .soluct.
Renderização do labirinto e do agente
- Desenho das paredes:
draw_maze(SDL_Renderer* ren, const MazeMap& m, int ox, int oy, int cell, int thick)percorre todas as células e desenha retângulos para cada parede presente (c.wall_n,c.wall_e,c.wall_s,c.wall_w). As posições são calculadas a partir do offset (ox,oy) e do tamanho de célula (cell).
static void draw_maze(SDL_Renderer* ren, const MazeMap& m, int ox, int oy, int cell, int thick=3) {
SDL_SetRenderDrawColor(ren, 0, 200, 0, 255);
for (int y = 0; y < m.height(); ++y) {
for (int x = 0; x < m.width(); ++x) {
const Cell& c = m.at(x,y);
const int x0 = ox + x*cell;
const int y0 = oy + y*cell;
if (c.wall_n) { SDL_Rect r{ x0, y0 - thick/2, cell, thick }; SDL_RenderFillRect(ren, &r); }
if (c.wall_s) { SDL_Rect r{ x0, y0 + cell - thick/2, cell, thick }; SDL_RenderFillRect(ren, &r); }
if (c.wall_w) { SDL_Rect r{ x0 - thick/2, y0, thick, cell }; SDL_RenderFillRect(ren, &r); }
if (c.wall_e) { SDL_Rect r{ x0 + cell - thick/2, y0, thick, cell }; SDL_RenderFillRect(ren, &r); }
}
}
}
- Agente e orientação:
draw_agent(...)pinta o corpo (retângulo vermelho central) e um traço indicando a orientação absoluta (heading∈ {0=N,1=E,2=S,3=W}).
static void draw_agent(SDL_Renderer* ren, Point p, int heading, int ox, int oy, int cell) {
SDL_SetRenderDrawColor(ren, 200, 0, 0, 255);
SDL_Rect body{ ox + p.x*cell + cell/4, oy + p.y*cell + cell/4, cell/2, cell/2 };
SDL_RenderFillRect(ren, &body);
SDL_SetRenderDrawColor(ren, 255, 180, 180, 255);
int cx = ox + p.x*cell + cell/2;
int cy = oy + p.y*cell + cell/2;
int hx = cx, hy = cy; const int d = cell/3;
if (heading == 0) hy -= d; else if (heading == 1) hx += d; else if (heading == 2) hy += d; else hx -= d;
SDL_RenderDrawLine(ren, cx, cy, hx, hy);
}
- Rastro de visita:
draw_trail(...)colore células visitadas com transparência (verde para caminho “atual/correto” e amarelo para backtracking). O estado é mantido emtrail[y*w + x]e atualizado no loop (ver 4.2).
static void draw_trail(SDL_Renderer* ren, const std::vector<uint8_t>& trail, int w, int h, int ox, int oy, int cell) {
SDL_SetRenderDrawBlendMode(ren, SDL_BLENDMODE_BLEND);
for (int y=0; y<h; ++y) for (int x=0; x<w; ++x) {
uint8_t s = trail[y*w + x]; if (!s) continue;
if (s == 1) SDL_SetRenderDrawColor(ren, 0, 220, 0, 90); else SDL_SetRenderDrawColor(ren, 255, 215, 0, 140);
SDL_Rect r{ ox + x*cell + 4, oy + y*cell + 4, cell - 8, cell - 8 };
SDL_RenderFillRect(ren, &r);
}
}
Loop principal, eventos e UI
O main(...) configura janela e renderer SDL2, cria um sidebar, carrega/gera o labirinto e roda um loop de eventos que controla execução, pausa e reinício. Pontos-chave:
- Janela/renderer e fonte:
SDL_CreateWindow,SDL_CreateRenderer;UIFont font = ui_font_init(14)(fonte opcional, com fallback gracioso). - Seleção inicial: lista
maze/vialist_maze_files()e exibe menu simples no centro; opção 0 gera aleatório e salva.maze; demais itens carregam arquivos existentes. - Botões:
UIButton btnStarteUIButton btnNewno sidebar; clique em “Iniciar” alterna entre pronto/rodando/parado; “Novo Labirinto” cria e salva outro.maze. - Fases:
enum class Phase { Ready, RunningExplore, RunningReplay, FinishedSuccess, FinishedFail }controla o estado da UI. - Temporização: avança um passo a cada ~250 ms (
now - last_step > 250), computa métricas (steps, collisions, score, tempo).
Trecho de avanço e desenho por frame:
<em>// avanço</em>
if (!paused && (now - last_step > 250) && (phase==Phase::RunningExplore || phase==Phase::RunningReplay)) {
last_step = now;
maze::SensorRead sr = make_sensor_read(map, agent, heading);
nav.observeCellWalls(agent, sr, heading);
nav.planRoute();
auto dec = nav.decidePlanned(agent, heading, sr);
<em>// aplica movimento, atualiza score, trail e logs...</em>
}
<em>// desenho</em>
draw_grid(ren, OX, OY, CELL, W, H);
draw_maze(ren, map, OX, OY, CELL);
draw_trail(ren, trail, W, H, OX, OY, CELL);
draw_agent(ren, agent, heading, OX, OY, CELL);
draw_sidebar(ren, font, sidebar, log, (win_h-200)/18);
draw_button(ren, font, btnStart);
draw_button(ren, font, btnNew);
- Teclas úteis:
ESCencerra;SPACEpausa/retoma;rreinicia tentativa no mesmo mapa. - Título da janela: exibe
steps,collisions,time,scoree estado(paused).
Persistência: .maze, .plan, .soluct
O simulador salva e carrega artefatos em JSON:
- .maze (mapa): salvo por
save_maze_json(path, map, entrance, goal_cell, entrance_heading, meta)e carregado porload_maze_json(...). Contém dimensões, paredes (por célula), célula de entrada/saída e orientação inicial, além de metadados de sessão (autor/data, etc.). - .soluct (solução): gerado ao atingir o objetivo. Usa
build_solution_json(...)esave_solution_versioned(current_map_file, content)para versionar a solução vinculada ao arquivo.maze. Inclui caminho final (lista dePoint), contagem de passos/colisões, tempo e custo. - .plan (plano de execução): log de cada passo, com decisão tomada, sucesso/colisão,
scoreacumulado e estado. Construído porbuild_plan_json(...)e salvo viasave_plan_versioned(...)tanto em sucesso quanto em falha.
Outras utilidades relacionadas:
ensure_dirs()cria diretórios esperados (maze/, possivelmenteplans/esolutions/).ensure_session_meta(...)ecollect_meta_default()garantem e preenchem metadados mínimos (identificação do autor/sessão) antes de salvar arquivos.list_maze_files()retorna os arquivos.mazedisponíveis para o menu de seleção.
Observação: os nomes das funções acima são chamados diretamente em main.cpp; suas implementações auxiliares residem no mesmo arquivo ou em utilitários locais do simulador.
Dicas de uso e reprodutibilidade
- Para obter o mesmo labirinto em execuções repetidas, substitua a semente do gerador (
std::mt19937 rng(123456u)) na etapa de geração (Cap. 3.4). - Para depuração rápida sem SDL, use
MazeMap::to_string_ascii()(Seção 2) e salve um.maze; o simulador conseguirá carregar e visualizar. - O rastro verde final é “limpo” ao concluir: o simulador recolore de amarelo os trechos que não pertencem ao caminho final e reforça o verde no caminho do objetivo.
Planejamento de Rota e Execução
Este capítulo detalha como o agente planeja e executa ações para alcançar a célula objetivo, usando o módulo Navigator em src/core/Navigator.cpp.
Visão geral do Navigator
- O
Navigatormantém:map_: mapa conhecido (atualizado por percepções via sensores).start_,goal_,has_goal_e dimensões do mapa.plan_: sequência de pontos (caminho) gerada por planejamento.seen_: contador de visitas por célula para favorecer exploração.heur_: pesos heurísticos para ações (vide Seção 6).
Observação do ambiente e atualização do mapa
Quando o simulador obtém leituras relativas de sensores (esquerda, frente, direita) e conhece a orientação absoluta (heading), o Navigator atualiza o MazeMap marcando paredes em direções absolutas correspondentes:
void Navigator::observeCellWalls(Point cell, const SensorRead& sr, uint8_t heading) {
auto set_dir = [&](char dir, bool free_flag){ map_.set_wall(cell.x, cell.y, dir, !free_flag); };
const char abs_dirs[4] = {'N','E','S','W'};
auto rel_to_abs = [&](int rel){ <em>// 0=Left,1=Front,2=Right</em>
int base = (int)heading;
int d = (rel==0) ? (base + 3) & 3 : (rel==1) ? base : (base + 1) & 3;
return abs_dirs[d];
};
set_dir(rel_to_abs(0), sr.left_free);
set_dir(rel_to_abs(1), sr.front_free);
set_dir(rel_to_abs(2), sr.right_free);
<em>// incrementa contador de visita na célula atual</em>
if (!seen_.empty() && map_.in_bounds(cell.x, cell.y)) {
int id = idx(cell.x, cell.y);
if (id >= 0 && id < (int)seen_.size() && seen_[id] < 255) seen_[id]++;
}
}
Isso garante consistência com MazeMap::set_wall() (Seção 2) e traduz corretamente do referencial relativo para o absoluto (grupo cíclico Z4 sobre direções).
Planejamento por BFS
O planejamento do caminho é feito sob demanda por planRoute(), que delega ao planejador de grade Planner::bfs_path(map_, start_, goal_) para obter um caminho curto (em número de passos) no grafo de células conhecidas:
bool Navigator::planRoute() {
if (!has_goal_) return false;
auto p = Planner::bfs_path(map_, start_, goal_);
if (!p) { plan_.clear(); return false; }
plan_ = *p;
return !plan_.empty();
}
Notas:
- O BFS considera vizinhos N/E/S/W sem paredes no
map_conhecido. À medida queobserveCellWalls()atualiza paredes, o próximo planejamento refletirá o novo conhecimento. - Complexidade do BFS: tempo O(W·H) no pior caso; espaço O(W·H).
Execução do plano e conversões de direção
Com um plano em plan_, a decisão por passo é feita por decidePlanned(current, heading, sr). A rotina:
- Localiza
currentnoplan_e infere a direção absoluta desejada até o próximo ponto (N/E/S/W). - Converte essa direção absoluta em uma ação relativa ao
headingatual:Forward/Left/Right/Back. - Gera candidatos apenas para direções livres segundo
sr(relativo), priorizando:- Células não vistas (
seen==0), depois as menos vistas - Alinhamento com o plano
- Desempate por pontuação heurística
score_for
- Células não vistas (
- Se não houver candidatos, retorna
Back.
Trechos centrais:
Decision Navigator::decidePlanned(Point current, uint8_t heading, const SensorRead& sr) {
auto plan_wanted_abs = [&]() -> char {
if (plan_.empty()) return 'X';
auto it = std::find_if(plan_.begin(), plan_.end(), [&](const Point& pt){ return pt.x==current.x && pt.y==current.y; });
if (it == plan_.end() || std::next(it) == plan_.end()) return 'X';
Point next = *std::next(it);
if (next.x == current.x && next.y == current.y-1) return 'N';
if (next.x == current.x+1 && next.y == current.y) return 'E';
if (next.x == current.x && next.y == current.y+1) return 'S';
if (next.x == current.x-1 && next.y == current.y) return 'W';
return 'X';
}();
const char abs_dirs[4] = {'N','E','S','W'};
auto rel_to_abs = [&](int rel){ int base=(int)heading; int d=(rel==0)?(base+3)&3:(rel==1)?base:(base+1)&3; return abs_dirs[d]; };
auto abs_to_rel_action = [&](char abs){
int base=(int)heading; int idx_dir=0; for (int i=0;i<4;++i) if (abs_dirs[i]==abs) { idx_dir=i; break; }
int rel = (idx_dir - base + 4) & 3; <em>// 0=Front,1=Right,2=Back,3=Left</em>
if (rel==0) return Action::Forward; if (rel==1) return Action::Right; if (rel==3) return Action::Left; return Action::Back;
};
struct Cand { Action a; int seen; bool matches_plan; };
std::vector<Cand> cands; cands.reserve(3);
auto push_cand = [&](int rel, bool free_flag){ if (!free_flag) return; char abs = rel_to_abs(rel);
int nx=current.x, ny=current.y; if (abs=='N') ny--; else if (abs=='E') nx++; else if (abs=='S') ny++; else if (abs=='W') nx--; int s=255;
if (!seen_.empty() && map_.in_bounds(nx,ny)) s = seen_[idx(nx,ny)]; cands.push_back(Cand{ rel==0?Action::Left : rel==1?Action::Forward : Action::Right, s, (abs==plan_wanted_abs) }); };
push_cand(0, sr.left_free); push_cand(1, sr.front_free); push_cand(2, sr.right_free);
if (!cands.empty()) {
std::stable_sort(cands.begin(), cands.end(), [&](const Cand& a, const Cand& b){
bool au=(a.seen==0), bu=(b.seen==0); if (au!=bu) return au; if (a.seen!=b.seen) return a.seen<b.seen;
if (a.matches_plan!=b.matches_plan) return a.matches_plan; return score_for(a.a, sr) > score_for(b.a, sr);
});
Decision d; d.action=cands.front().a; d.score=score_for(d.action, sr); return d;
}
Decision d; d.action=Action::Back; d.score=score_for(d.action, sr); return d;
}
Esse mecanismo cria um equilíbrio entre seguir o plano (quando ele existe e é compatível com o conhecimento atual), explorar o desconhecido e manter preferências heurísticas.
Heurística e reforço durante a execução
Após cada ação, o simulador pode aplicar recompensas/punições aos pesos internos via applyReward(...), que delega ao atualizador definido em Learning.hpp (Seção 6):
void Navigator::applyReward(Action a, float reward) {
uint8_t idx = 0;
switch (a) {
case Action::Right: idx = 0; break;
case Action::Forward: idx = 1; break;
case Action::Left: idx = 2; break;
case Action::Back: idx = 3; break;
}
update_heuristic(heur_, idx, reward);
}
No simulador, avanços “Forward” bem-sucedidos recebem pequenas recompensas, colisões recebem penalidades, e giros têm leves custos — refletindo preferências de eficiência.
Exemplo passo a passo (síntese)
- Em cada tick, o simulador lê
SensorReadrelativo da célula atual e orientação (heading). observeCellWalls()atualizamap_(aberturas/paredes) eseen_.planRoute()é invocado a cada passo para refletir conhecimento crescente.decidePlanned()escolhe a ação considerando plano, exploração e heurística.- A ação é aplicada; métricas e rastro são atualizados;
applyReward()ajustaheur_.
Complexidade por tick (excluindo render): O(W·H) no pior caso devido ao BFS, mas praticada sobre mapas moderados (ex.: 16×12) a latência é pequena, adequada à simulação interativa.
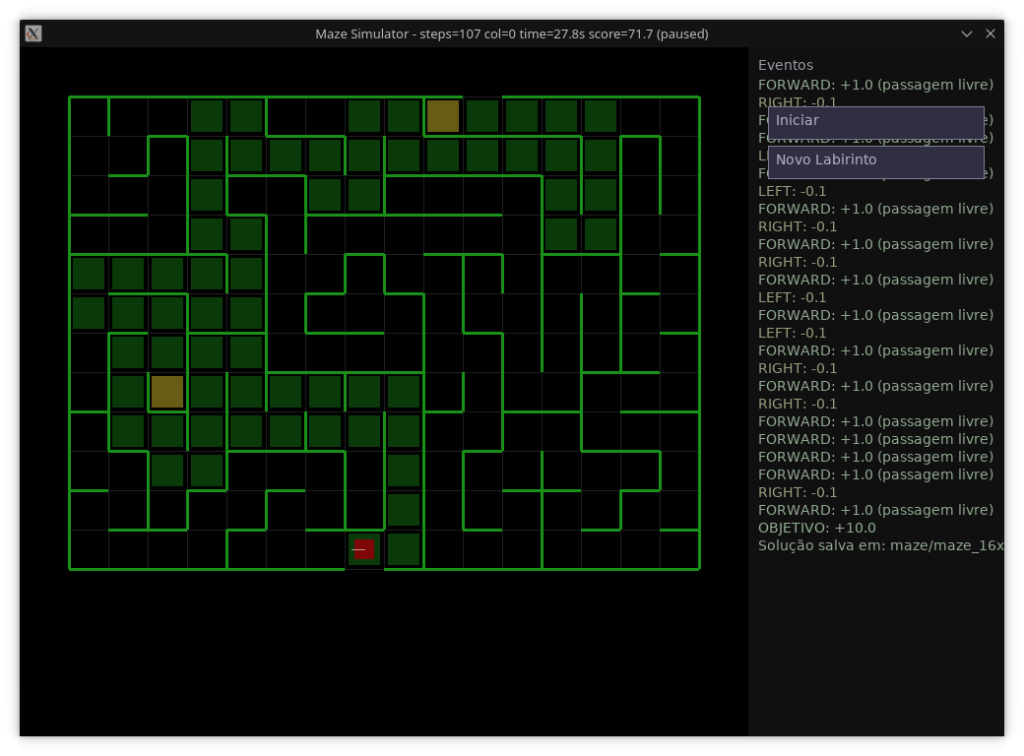
Heurísticas e Aprendizado
Esta seção descreve como os pesos de ação influenciam decisões e como são atualizados online por reforço simples. O código-fonte está em src/core/Learning.hpp e é utilizado por Navigator (src/core/Navigator.cpp).
Estrutura de pesos Heuristics
Cada ação possui um peso associado, inicializado em 1.0:
struct Heuristics {
float w_right{1.0f}; <em>// virar à direita</em>
float w_front{1.0f}; <em>// seguir em frente</em>
float w_left{1.0f}; <em>// virar à esquerda</em>
float w_back{1.0f}; <em>// dar ré</em>
};
Esses pesos representam “preferência” relativa quando a direção está livre.
Atualização por recompensa update_heuristic()
Regra online simples com taxa de aprendizado fixa e saturação na faixa [0.2, 3.0]:
inline void update_heuristic(Heuristics& h, uint8_t action, float reward) {
const float lr = 0.05f; <em>// learning rate</em>
switch (action) {
case 0: h.w_right += lr * reward; if (h.w_right < 0.2f) h.w_right = 0.2f; if (h.w_right > 3.0f) h.w_right = 3.0f; break;
case 1: h.w_front += lr * reward; if (h.w_front < 0.2f) h.w_front = 0.2f; if (h.w_front > 3.0f) h.w_front = 3.0f; break;
case 2: h.w_left += lr * reward; if (h.w_left < 0.2f) h.w_left = 0.2f; if (h.w_left > 3.0f) h.w_left = 3.0f; break;
case 3: h.w_back += lr * reward; if (h.w_back < 0.2f) h.w_back = 0.2f; if (h.w_back > 3.0f) h.w_back = 3.0f; break;
}
}
No simulador, exemplos de recompensas/punições aplicadas (ver Cap. 4):
- Forward bem-sucedido: +1.0
- Colisão: −5.0
- Giros (Left/Right): −0.1; Back: −0.2
Esses valores moldam o comportamento para favorecer progresso e evitar colisões/ziguezagues.
Como os pesos afetam a decisão (score_for)
O Navigator converte pesos em uma escala 0..10, respeitando bloqueios dos sensores:
uint8_t Navigator::score_for(Action a, const SensorRead& sr) const {
float base = 0.0f;
switch (a) {
case Action::Right: base = sr.right_free ? heur_.w_right : 0.1f; break;
case Action::Forward: base = sr.front_free ? heur_.w_front : 0.1f; break;
case Action::Left: base = sr.left_free ? heur_.w_left : 0.1f; break;
case Action::Back: base = (!sr.left_free && !sr.front_free && !sr.right_free) ? heur_.w_back : 0.2f; break;
}
float score = (base / 3.0f) * 10.0f;
if (score < 0.f) score = 0.f; if (score > 10.f) score = 10.f;
return static_cast<uint8_t>(score > 10.f ? 10 : (score < 0.f ? 0 : score));
}
Impactos práticos:
- Ao reforçar “Forward” após sucessos, o sistema tende a priorizar avançar quando possível.
- Penalizar colisões reduz a propensão a insistir em frente bloqueada e incentiva ajustes de rumo.
- Pesos de “Left/Right” modulam a preferência lateral em empates; “Back” é reservado como último recurso.
Dinâmica, saturação e estabilidade
- A saturação em [0.2, 3.0] evita extremos que poderiam “travar” a política.
- A taxa
lr=0.05é conservadora, permitindo adaptação gradual sem oscilações grandes. - Como o planejamento (BFS) é refeito a cada passo (Cap. 5), o aprendizado atua mais como viés de desempate/exploração do que como única política de navegação.
Exemplo ilustrativo
Suponha pesos iniciais todos em 1.0. Em uma sessão com muitos avanços retos e poucas colisões:
w_fronttende a crescer (p.ex., 1.0 → 1.5), elevandoscore_for(Forward)sempre que a frente está livre.- Colisões ocasionais ao ir “Forward” reduzirão esse ganho, estabilizando perto do intervalo útil (≈1.2–2.0, dependendo do cenário).

Sensores e Percepção (IR + ADC no RP2040)
Nesta seção detalhamos a camada de percepção por sensores IR reflexivos, conforme src/hal/IRSensorArray.hpp e src/hal/IRSensorArray.cpp.
Arranjo e leitura de 3 sensores IR
- Estrutura de valores normalizados
IRValues:
struct IRValues {
float left{1.0f}; <em>// 0..1</em>
float front{1.0f}; <em>// 0..1</em>
float right{1.0f}; <em>// 0..1</em>
};
- Classe
IRSensorArrayrecebe os canais ADC dos três sensores e inicializa o ADC/GPIO automaticamente quando aplicável:
IRSensorArray::IRSensorArray(uint8_t adc_left, uint8_t adc_front, uint8_t adc_right)
: ch_left_(adc_left), ch_front_(adc_front), ch_right_(adc_right) {
adc_init();
auto init_adc_gpio_if_valid = [](uint8_t ch){ if (ch <= 3) adc_gpio_init((uint)(26 + ch)); };
init_adc_gpio_if_valid(ch_left_);
init_adc_gpio_if_valid(ch_front_);
init_adc_gpio_if_valid(ch_right_);
}
Observação: no RP2040, ADC0..ADC3 mapeiam para GPIO26..GPIO29. O ADC possui 12 bits efetivos; a leitura bruta é normalizada para [0,1]:
static inline float read_adc_norm(uint8_t ch) {
adc_select_input(ch);
uint16_t raw = adc_read(); <em>// 12 bits</em>
return (float)raw / 4095.0f;
}
Suavização por média exponencial (EMA)
Para reduzir ruído, a classe aplica EMA com fator alpha configurável (padrão 0.25):
void setSmoothing(float alpha) { alpha_ = (alpha <= 0.f) ? 1.f : (alpha > 1.f ? 1.f : alpha); }
IRValues IRSensorArray::readAll() const {
IRValues raw{ read_adc_norm(ch_left_), read_adc_norm(ch_front_), read_adc_norm(ch_right_) };
if (!inited_) { filt_ = raw; inited_ = true; return filt_; }
auto ema = [a = alpha_](float prev, float x){ return prev + a * (x - prev); };
filt_.left = ema(filt_.left, raw.left);
filt_.front = ema(filt_.front, raw.front);
filt_.right = ema(filt_.right, raw.right);
return filt_;
}
Matematicamente, para cada sensor y_t = y_{t-1} + α (x_t - y_{t-1}), com α ∈ (0,1]. Valores menores de α resultam em resposta mais lenta (mais filtrada). Regra prática: dado um período de amostragem dt e uma constante de tempo desejada τ, tomar α ≈ dt / (τ + dt).
Exemplo: com dt ≈ 150 ms e τ ≈ 0.5 s, α ≈ 0.23.
Do analógico ao “livre/bloqueado” (integração)
- A camada HAL fornece apenas valores contínuos [0..1]. A decisão “livre/bloqueado” é tomada em níveis superiores do sistema, de acordo com a estratégia e a calibração do robô real.
- No simulador, as leituras de sensores são sintetizadas a partir do mapa (vide
make_sensor_read(...)emsimulator/main.cpp), convertendo paredes absolutas em flags relativasleft_free/front_free/right_freeconforme oheadingatual. - Em hardware, tipicamente define-se um limiar
θ(por exemplo,θ ≈ 0.35–0.6, a depender do arranjo óptico e da cor da parede/chão) para discretizar:flag = (valor < θ)ou(valor > θ), conforme a convenção elétrica do sensor (mais reflexão → maior tensão, etc.). Essa escolha deve ser validada experimentalmente.
Boas práticas de calibração
- [offset/gain]: execute uma rotina de calibração medindo níveis “fundo” (sem obstáculo) e “parede” para cada sensor; ajuste o limiar por sensor.
- [faixa dinâmica]: garanta que a iluminação ambiente não sature o ADC; se necessário, use modulação (PWM no emissor IR) e detecção síncrona.
- [latência x ruído]: escolha
αcompatível com a velocidade do robô. Filtragem excessiva pode atrasar reações em corredores curtos.
Métricas, Logs e Reprodutibilidade
Este capítulo resume como o simulador registra artefatos e métricas para permitir análise e repetição de experimentos.
Artefatos persistidos
- Arquivo
.maze: mapa do labirinto gerado ou carregado. Usado pelo simulador para reconstruir paredes/aberturas. Pode ser produzido pelo gerador (Cap. 3) e reusado para testes comparáveis. - Arquivo
.soluct: solução final do episódio (trajeto do início ao objetivo), armazenando a sequência de células do caminho vencedor ao término. Serve para validação visual e estatística (comprimento do caminho, razão volta/caminho ótimo, etc.). - Arquivo
.plan: log de planejamento/execução por passo, com informações do estado do agente, decisão tomada e, quando disponível, rota planejada vigente. Útil para depuração do ciclo observar-planejar-agir (Cap. 5).
Prática recomendada: mantenha um diretório maze/ com conjuntos de .maze e respectivos .plan/.soluct para cada execução controlada.
Métricas expostas no simulador
O simulador mantém e exibe, na barra lateral, indicadores como:
- Passos: número de ações executadas (ticks válidos).
- Colisões: contagem de tentativas de avanço contra parede.
- Tempo: tempo corrido do episódio (ms/s), sincronizado com a taxa de atualização.
- Score: agregação simples ponderando progresso e penalidades (por exemplo, +1 por avanço, −5 por colisão, penalidades leves por giros). O score é útil para comparar episódios em mapas iguais.
Essas variáveis são atualizadas no loop principal do simulador (Cap. 4) a cada tick, junto com a renderização e o estado da simulação (Ready/Running/Finished).
Reprodutibilidade
Para reproduzir resultados:
- Semente do gerador: fixe a semente do
std::mt19937na geração do labirinto (ver Cap. 3.4). Ex.:std::mt19937 rng(123456u);. - Versões e parâmetros: registre versões do código, dimensões do labirinto e parâmetros relevantes (p. ex.,
alphado EMA dos sensores, pesos iniciais de heurística). - Persistência de artefatos: salve
.maze(entrada),.plan(processo) e.soluct(resultado) no mesmo diretório para auditoria e análise futura.
Fluxos comuns
- Gerar um labirinto fixo e salvar:
Geração (Cap. 3) -> salvar maze_16x12_xxxxx.maze
- Executar múltiplos episódios com a mesma
.mazevariando parâmetros (ex.:alphado EMA ou pesos iniciais da heurística) e salvar.plan/.soluctde cada execução. - Comparar métricas: passos, colisões, tempo e score; verificar comprimento do caminho final (
.soluct) e consistência com a rota do BFS planejado (Cap. 5).
Exemplos de análise
- Curva de score ao longo dos passos (derivada do
.plan), destacando colisões como quedas abruptas. - Distribuição do
w_front,w_left,w_right,w_backao longo do episódio (Cap. 6) para observar adaptação. - Diferença entre rota planejada e rota executada quando há divergências (erros de percepção/ruído ou exploração deliberada).
Referências
- Geração de labirintos (Recursive Backtracker / DFS):
- J. Buck. “Maze Generation: Recursive Backtracker.” Disponível em diversos tutoriais e implementações educacionais.
- Wikipedia: “Maze generation algorithm” (seções sobre backtracking/DFS e propriedades de labirintos perfeitos).
- Busca em largura (BFS) em grids:
- T. H. Cormen et al., “Introduction to Algorithms” (CLRS), cap. sobre Grafos e BFS.
- Visualizações educacionais em grids (ex.: pathfinding em matrizes ortogonais com 4 vizinhos).
- SDL2 (renderização e eventos):
- SDL2 Wiki: https://wiki.libsdl.org/ – Documentação de
SDL_Renderer,SDL_Window, handling de eventos, fontes e temporização.
- SDL2 Wiki: https://wiki.libsdl.org/ – Documentação de
- RP2040 / ADC:
- Raspberry Pi Pico Datasheet (RP2040): capítulos sobre ADC e GPIO.
- Raspberry Pi Pico C/C++ SDK (pico-sdk): headers
hardware/adc.h, exemplos oficiais.
- Processamento de sinais simples (EMA):
- Notas de engenharia sobre filtro exponencial (IIR de primeira ordem):
y_t = y_{t-1} + α (x_t - y_{t-1}).
- Notas de engenharia sobre filtro exponencial (IIR de primeira ordem):
- Código do projeto (citações diretas neste artigo):
simulator/main.cpp: geração do labirinto, laço principal, renderização, persistência.maze/.plan/.soluct,make_sensor_read(...).src/core/Navigator.cpp: observação de paredes, planejamento por BFS (planRoute()), decisão (decidePlanned()), escores e recompensas.src/core/MazeMap.hpp: representação do grid, invariantes e utilidades.src/core/Learning.hpp:Heuristicseupdate_heuristic().src/hal/IRSensorArray.hpp/.cpp: leitura, normalização e filtragem EMA dos sensores IR.